时间:2024-08-09 来源:网络搜集 关于我们 0
当地时间2023年10月4日,英特尔(Intel)通过官网正式宣布,将负责开发英特尔的 Agilex、Stratix 和其他 FPGA 产品的可编程解决方案事业部(Programmable Solutions Group,PSG)拆分,作为独立业务运营,目标是在两到三年后IPO中出售部分业务。PSG的前身即为大名鼎鼎的全球第二大FPGA供应商Altera公司,其在1984年发明了世界上第一个可编程逻辑器件。2015年5月底英特尔宣布以167亿美元完成了对Altera的收购,成为了其后来的PSG部门,这也是英特尔史上规模最大的一笔收购。随后在2020年,英特尔的竞争对手AMD也宣布以350亿美元的估值收购全球第一大FPGA供应商赛灵思(Xilinx),这笔芯片行业创纪录的巨额并购交易,获得美国、中国等主要市场监管部门的批准,耗时一年半有余才尘埃落定。
FPGA两大巨头先后被CPU两大巨头收购,其背后的本质原因是两大巨头想通过FPGA补强其最赚钱的数据中心业务。八年时间,沧海桑田,度过七年之痒后,Intel与Aletera正式官宣”分手“。在此过程中,我们也注意到一个非常有趣的现象,即在AMD反复宣传Xilinx的收购对其数据中心业务有巨大帮助的额同时,为什么Intel要拆分他们的Altera?无论是作为商业世界的参与者、观察者,还是作为投资者,在面对一个行业现象时(尤其是这一现象时行业巨头展现的),我们不应浅尝辄止,满足于走马观花、看个热闹,而是应该深入考究这一现象背后的原因,力求拥有自己的独立思考逻辑框架。
需要说明的是,关于Intel为什么拆分FPGA业务,中科院计算所的老师、也是Intel出身的行业从业者老石谈芯在其B站视频《英特尔为何放弃FPGA:百亿收购失败?全网最深度解读》中已做过非常精彩的评述,大家有兴趣可以去看看。在此作为理科出身的金融从业者,我将从另一个角度出发谈一谈自己的理解,虽有班门弄斧之嫌,但也不失为自己思考的一个总结。我们将分三个部分对这一问题进行探讨:首先是梳理数据中心“选芯”史,即随着数据中心的发展,不同种类芯片的选择是如何进行的,以考察各类芯片在数据中心中的作用;其次回答为什么AMD反复宣传FPGA对其数据中心业务发展的帮助;最后简单分析为什么Intel选择拆分FPGA业务。
1、数据中心“选芯”史
要梳理数据中心的芯片,首先要明白什么是数据中心。根据《中国信通院中国第三方数据中心运营商分析报告》的定义,数据中心作为数据产生、汇聚、融合、传输的重要场所,是承载算力的物理实体,是传统产业数字化转型的催化剂,是数字产业快速发展的动力引擎,是我国新基建的核心组成部分。专业报告中的定义用词准确,但相应地不够通俗易懂。对上面定义翻译翻译就是,数据中心是一堆服务器的集合,由于服务器的核心又是芯片,因此数据中心本质上可以视作芯片的资源池。
数据中心的芯片最重要的是逻辑芯片。我们在《半导体系列5-半导体行业研究:集成电路之数字芯片中的逻辑芯片》中已经介绍过,逻辑芯片主要包括四大类:CPU、GPU、ASIC、FPGA,数据中心的选芯也主要基于这四类芯片进行。
我们需要知道,技术的进步往往是在实践中为解决一个个需求而产生的,因此并不是一开始就有了这四类逻辑芯片。相反地,起初的计算机只使用CPU,此后随着CPU算力达到瓶颈、通用计算时代终结,人们开始发明了其他架构的芯片。这也是为什么近年来诸如TPU、MPU、DPU等“X”PU们层出不穷的核心原因。
具体地说,随着我们信息社会从互联网时代向物联网时代发展,万物互连,万物智能,海量数据对算力产生了海量需求,尤其是自2010年AI兴起,AI模型训练所需要的算力更是爆发式增长。根据IDC 统计,全球算力需求平均每 3.5 个月翻一倍。
另一方面,从发明以来CPU算力的提升主要依赖两大法宝:提高时钟频率和增加内核数量,但两者都在面临瓶颈。对于前者而言,虽然越高的时钟频率意味着每秒可执行的运算次数越高,但随着电压下降到0.6v的“底限”,Dennard Scaling(Dennard缩放定律)在05年开始崩溃,再提高时钟频率就会使得功耗以指数级别增长,从而击破功耗预算;对于后者而言,由于核间调度有功耗和时延,而数据中心的散热技术约束了功率增长,将会导致处理器上许多核无法同时工作(即暗硅效应),核数的增长也遇到了瓶颈。
在此情况下,算力提升与数据增幅呈现巨额剪刀差。从CPU性能与网络带宽的过往发展趋势来看:网络带宽CAGR从2010年前的30%,提升至当前的45%;与之相对应的CPU性能CAGR从2010年前的23%,下降至当前的3.5%;RBP指标从1附近上升到10以上,远期将超30倍,CPU应对网络带宽增长带来的计算需求压力不断增大。因此,人们开始放弃“一个CPU打天下”的念头,决定扩充芯片资源池的种类,将某些重复的场景卸载到专用的加速器,为CPU“减压”,以达到降低功耗、提升性能的目的,由此产生了众多“XPU”。
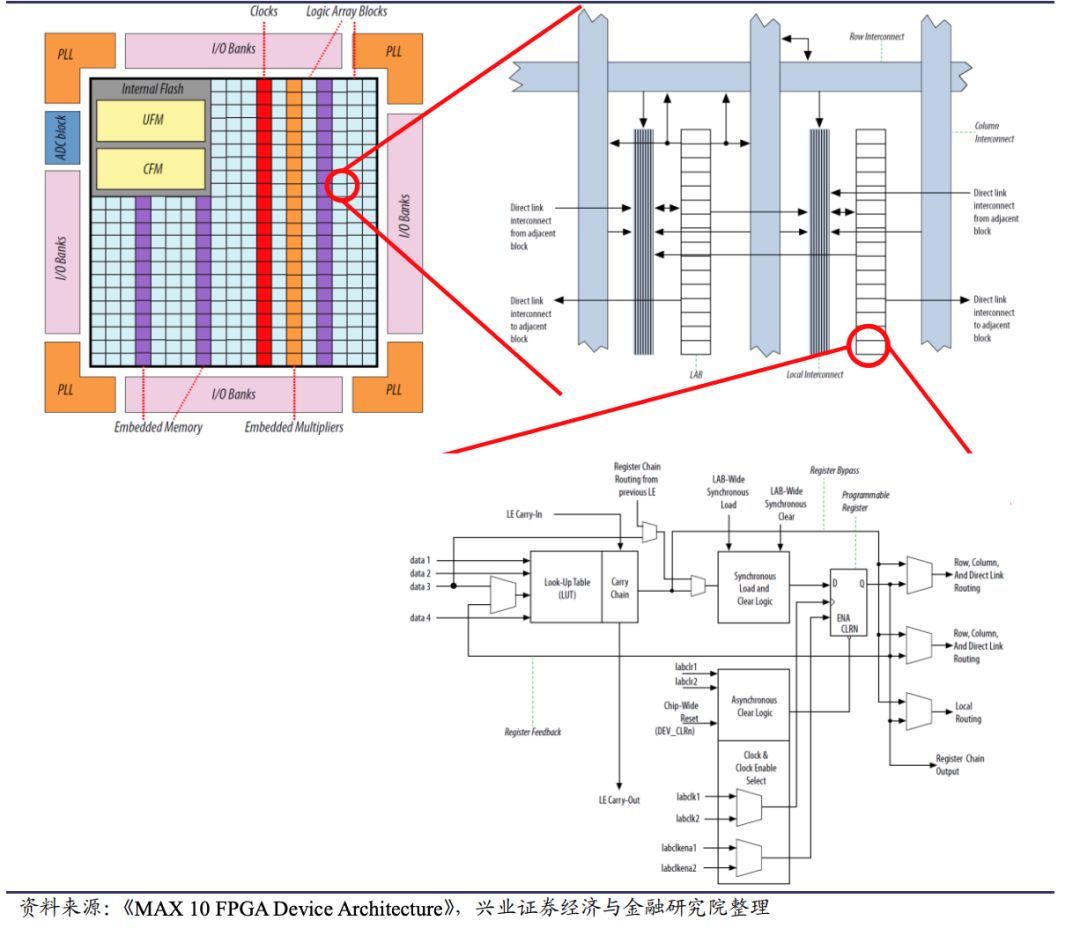
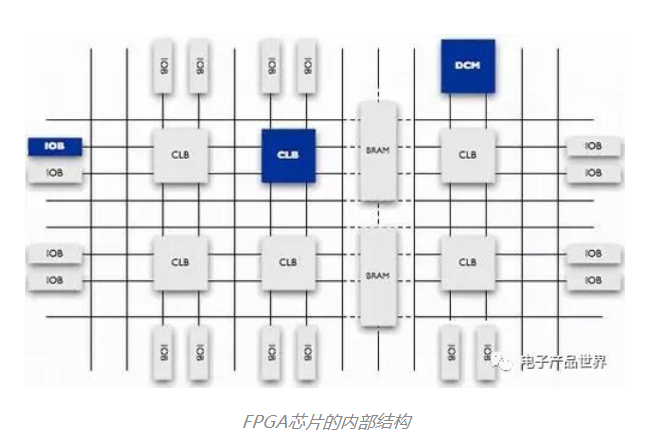
要想突破CPU的能力瓶颈,就需要进行芯片架构设计上的突破。从架构来看,CPU是冯诺依曼架构下的处理器,遵循“Fetch(取指)-Decode(译码)- Execute(执行)- Memory Access(访存)-Write Back(写回)”的处理流程,该处理流程称为SISD(Single Instruction Single Data)GPU虽然也是冯诺依曼架构,但其遵循SIMD(Single Instruction Multiple Data)的处理方式,可以在多个线程上进行统一处理。FPGA则是由用户自定义处理流程,可以直接决定片上的CLB(Configurable Logic Block,可编程逻辑块)是如何相连的,数十万个CLB可以独立运算,即SIMD、MISD(Multiple Instruction Single Data)和MIMD(Multiple Instruction Multiple Data)的处理都可以在FPGA实现。ASIC则是专用集成电路,具有定制化的架构属性。
SISD的处理方式决定了CPU擅长决策和控制,但在并行处理任务中效率较低。GPU去除了现代CPU中分支预测、乱序执行、存储预取等模块,也减少了许多cache的空间,其经简化后的“核”能实现非常大规模的并行运算,并且节省了大部分CPU分支预测、任务重排的时间。因此,GPU非常适用于诸如图形图像、深度学习、矩阵运算等方面的计算。FPGA由于处理流程已经映射到硬件上,不需要再额外花费时间获取和编译指令,同样不需要像CPU一样花费时间在乱序执行等步骤,因此在数据处理中具有非常高的实时性。ASIC的定制化保证了其在特定场景下效率也更高。
因此相比于CPU,三者的效率都更高,所不同的是ASIC的硬伤更明显,那就是极其不灵活,虽然限定场景内性价比高,但一旦场景改变,ASIC就很难应对。因此只有头部大企业才有能力和资本使用,如TPU就是谷歌为张量计算专门开发的。对于大部分数据中心而言,主要考虑的还是GPU与FPGA,我们接下来的讨论也聚焦于此。
数据中心给CPU减压进行的选芯也主要是基于这三者进行的,也为各类芯片选定了它们的生态位,即CPU承担决策和控制、GPU承担计算密集型任务,而将原本属于CPU的IO数据的预处理和后处理,包括网络类任务(虚拟网络、IPSec等 )、存储类任务(分布式存储、数据加解密、数据压缩、数据冗余算法等 )、虚拟化加速 (虚拟化整体Ofoad,业务管理分离 )、安全和认证类的任务 (Root ofTrust 等).卸载给其他芯片,人们将这种因数据中心而生的芯片称为DPU(Data Processing Unit,数据处理单元或数据处理器)。DPU也被称为大数据时代的”第三颗主力芯片“。
新的芯片选定也带来了数据中心整体架构的重构,数据量大于计算量之后,DPU应运而生,整个计算的模式就从计算驱动变成了数据驱动。在DPU出现之前,网络数据处理逻辑以CPU为中心,按顺序执行,即传输终点为GPU、DSA(Domain Specific Architecture,特定领域架构,即特定领域定制芯片)、主存的数据流都必须经过CPU调度。DPU出现后则将数据集中处理、调度,不仅能够缩短数据所需经过的路径、减轻CPU负担,还能在提高数据处理效能的同时,降低其他计算芯片性能损耗,最终显著提升计算系统整体性能。
DPU具有独立计算单元,可按技术路线划分为三大类,包括基于ASIC、FPGA和SoC三大类,其中SoC技术路线是基于MP (众核)设计的DPU(如 FPGA + CPU、ASIC+CPU),其又有两条分支,包括SoC-GP (通用处理器)和SoC-NP (网络处理器)。不同技术路线的产品各具优劣,综合来看,SoC为DPU最佳的技术路线。
2、FPGA对AMD数据中心业务发展的帮助
通过上面的介绍我们已经知道数据中心三大核心芯片包括CPU、GPU与DPU,而FPGA又是DPU的最主要的实现方式之一。在此,我想深究一下FPGA与AMD本来的业务GPU的详细区别(这也决定了其在数据中心的生态位)后,再来回答这一问题会更加清晰。这些区别的核心原因仍是两者的架构不同。
首先是核数和频率,GPU的架构在电路实现上是基于标准单元库,因此想增加核数只要增加芯片面积就行。标准单元库也决定了其在关键路径(即芯片中一个时钟周期内延迟最长的路径,其直接决定了电路最高运行速度)上可以定制电路和布线,甚至必要时可以让FAB厂依据设计需求微调工艺制程,因此可以让许多核同时跑在非常高的频率。FPGA里面的逻辑单元是基于SRAM-查找表,其性能较GPU里面标准逻辑单元要差很多,一旦型号选定了逻辑资源上限就确定了(浮点运算在FPGA里会占用很多资源),核数有限。而且,FPGA的布线资源也受限制,有些线必须要绕很远,也会限制其时钟频率。
其次是功耗。GPU依赖片外存储的处理流程,以英伟达的GPU为例,使用CUDA进行训练,主要有四个步骤:(1)将数据从CPU的DRAM复制到GPU的存储中;(2)CPU 加载需要进行的计算即Kernel到GPU中;(3)GPU执行CPU发送过来的指令;(4)GPU将结果最终存回CPU的DRAM中,再进行下一个Kernel的计算。因此,CUDA涉及了两次存储读写。而FPGA可以将第一个Kernel的结果缓存到片上星罗棋布的BRAM中,完全可以不需要读写外部存储就能完成整个算法。由于读取DRAM所消耗的能量是SRAM的100倍以上,是加法的6400倍,GPU这一需要频繁读取DRAM的处理,使其功耗远高于FPGA。一片FPGA的典型功耗通常是30W ~ 50W,而单片GPU功耗就可以高达250W ~ 400W。
最后是时延和灵活性。GPU通常需要将不同的训练样本划分成固定大小的“Batch(批次)”,为了最大化达到并行性,需要将数个Batch都集齐,再统一进行处理。FPGA的架构是无批次(Batch-less)的,可以根据数据特点确定处理方式,不需要像GPU一样将输入的数据划分成Batch,每处理完成一个数据包,就能马上输出。GPU需要等待批次的特点,使其时延要高于FPGA。灵活性方面,GPU的接口单一,只有PCIe一种,而FPGA的可编程性使其能与任何的器件进行通信,能够适应任何的标准和非标准的接口。
在数据中心服务器端,峰值性能、灵活性、平均性能、功耗和能效比这几个指标是决定采取哪一个芯片的核心考量。
FPGA在功耗、灵活性、时延方面显然好于GPU。因此FPGA在架构上可以根据特定应用优化所以比GPU有优势,但是GPU的运行速度(>1GHz) 相比FPGA有优势 (~200MHz)。除了芯片性能外,GPU相对于FPGA还有一个优势就是内存接口。GPU的内存接口(传统的GDDR5,最近更是用上了HBM和HBM2)的带宽远好于FPGA的传统DDR接口(大约带宽高4-5倍)。所以对于平均性能,看的就是FPGA加速器架构上的优势是否能弥补运行速度上的劣势。如果FPGA上的架构优化可以带来相比GPU架构两到三个数量级的优势,那么FPGA在平均性能上会好于GPU。如百度在HotChips上发布的文章显示,在矩阵运算等大批量计算上GPU的平均性能远好于FPGA;但是在处理服务器端的少量多次处理请求(即频繁请求但每次请求的数据量和计算量都不大)的场合下,FPGA平均性能更好。
经过以上的分析,我们很容易得出结论,在数据中心和人工智能领域,GPU更适合承担高算力任务,FPGA更适合承担低算力任务和网络任务。同时两者不是非此即彼的关系,而是相互补充、分工合作的关系。因此AMD收购赛灵思以及反复宣传FPGA对其数据中心业务(也是其最赚钱的业务部门)是非常正常的。
首先,收购赛灵思获得FPGA业务后对AMD整个产品生态都是一个非常重要的补充。AMD获得了行业龙头赛灵思的人才和能力,与自有的CPU、GPU一起集齐了三个主力芯片,相当于拥有了完整的高性能计算体系,实现1+1+1>3的结果,并且一举超过了老对手英特尔,成为FPGA领域占有率最大的公司。此外,赛灵思ACAP(自适应计算加速平台)芯片技术,也为数据中心芯片业务未来的发展提供了想象空间和技术储备。因为不要忘了,技术的发展不是直线式的,而是螺旋式上升、波浪式前进的。
其次,同时拥有CPU、GPU和FPGA能力的AMD,也为新的产品形态拓展提供了可能。我们上面已经谈到,基于SoC技术路线的DPU可能为最佳路径。SoC技术路线的核心是通过堆叠处理器核提高可编程性,实现整体性能的提高,且能够降低成本。收购FPGA业务恰好给了AMD更宽广的能力范围。比如现在FPGA一般都以PCIe扩展卡的形式与CPU。这其实并不是很方便,也很影响性能和功耗。英特尔曾经希望把CPU和FPGA两个芯片做在一起,但因各种原因没有成功。如果AMD借此机会尝试成功,那将大大提高其在数据中心的竞争力。
最后,收购赛灵思意味着除了数据中心之外,AMD将借助FPGA业务进入工业、汽车、通信等等细分市场,进一步将触手扩展到更多领域。这是因为FPGA的低时延和低功耗优势非常适用于边缘计算领域(受限于网络条件和时延,许多决策来不及上传云端,只能本地执行,这就是边缘计算,其通常面临时延和功耗两大约束)。AMD本身的CPU和GPU在边缘计算领域相对于FPGA处于劣势,收购FPGA能补上其应用领域的短板。
3、Intel为何拆分FPGA业务
在回答这个问题之前,我们需要再次强调,技术的发展和技术路径的选择不是直线式的,而往往是螺旋式的上升、波浪式的前进。因此需要明白Intel收购FPGA业务和现在要拆分FPGA业务时面临的环境变化、技术路线变化可能是其拆分FPGA业务的主因。即确如AMD所说FPGA对数据中心有帮助,但现在的帮助并不如收购时想象的那么核心。
如上所说,FPGA相对于GPU的优势是灵活性和低功耗,尤其是灵活性使得它可以根据不同的应用需要,改变自己的功能,性能还比CPU要高,功耗比GPU要低(因此成本也低),适用范围比专用芯片ASIC要广。基于这种优势,其特别适用于那种仍在蓬勃发展中、但相关的标准和算法还没有实现统一的场景。这恰恰是在Intel收购Altera,甚至是AMD收购Xilinx的彼时,大数据和人工智能领域之时的情况。这也是它之前人工智能和数据中心领域拥有无限可能的核心原因,甚至有可能承担训练芯片的任务。
在大模型出来之后,人工智能的标准和算法似乎突然清晰起来各家也对此倾情押注,不计成本展开军备竞赛。在AGI的大模型框架下,智能随着规模涌现,算力成为绝对的王道,特别是在数据中心和大模型训练领域,峰值性能、平均性能成为压倒性的指标考量。FPGA独特的灵活性和低成本优势已经被GPU简单粗暴的算力优势降维打击。其成为训练芯片的可能性大大降低,应用依然是搭配CPU承担任务卸载功能或者是承担边缘侧的推理任务功能。
此外叠加FPGA超长的生命周期,其在数据中心的使用量天花板肉眼可见的降低,这也使得这个业务变成稳定的现金奶牛,显得不那么性感了。再加上Intel未来几年2000亿美元投资计划带来的现金需求,都是促成Intel拆分FPGA业务的原因。
至此,我们分析了数据中心的主要芯片,也深刻体会了技术路线之间不断竞争带来的剧烈变革。我们坚定相信变革是好的,坚定拥抱技术进步和现金生产力,因为往往是它们带来无数新的投资机会,也会给所有人带来普惠的福祉。历史证明,虽有坎坷,但人类对新技术总会应用得当。