时间:2025-04-01 来源:FPGA_UCY 关于我们 0
1:概要
时间:2024.07.23 全天
地点:深圳万恰酒店五楼
主题内容:主要还是 二代的推介吧,还有就是针对AIE的开发做了一些介绍,和去年的内容对比,没有什么惊喜。
2:会议议程:

3:会场展台 3.1:AMD官方展台 3.1.1: 800G 以太网

高带宽:的总带宽。用于大规模数据传输的场景:如:数据中心互联,高性能计算(HPC),大数据分析(金融服务)。这种大规模的集群计算环境。
采用 系列的SoC芯片(),A72,R5 2 Arm处理器,3KK 逻辑单元,400个AIE,超过9000个DSP单元。
高速I/O 112G 支持(并行8个,可以达到 800G)
3.1.2:AI引擎的STAP算法
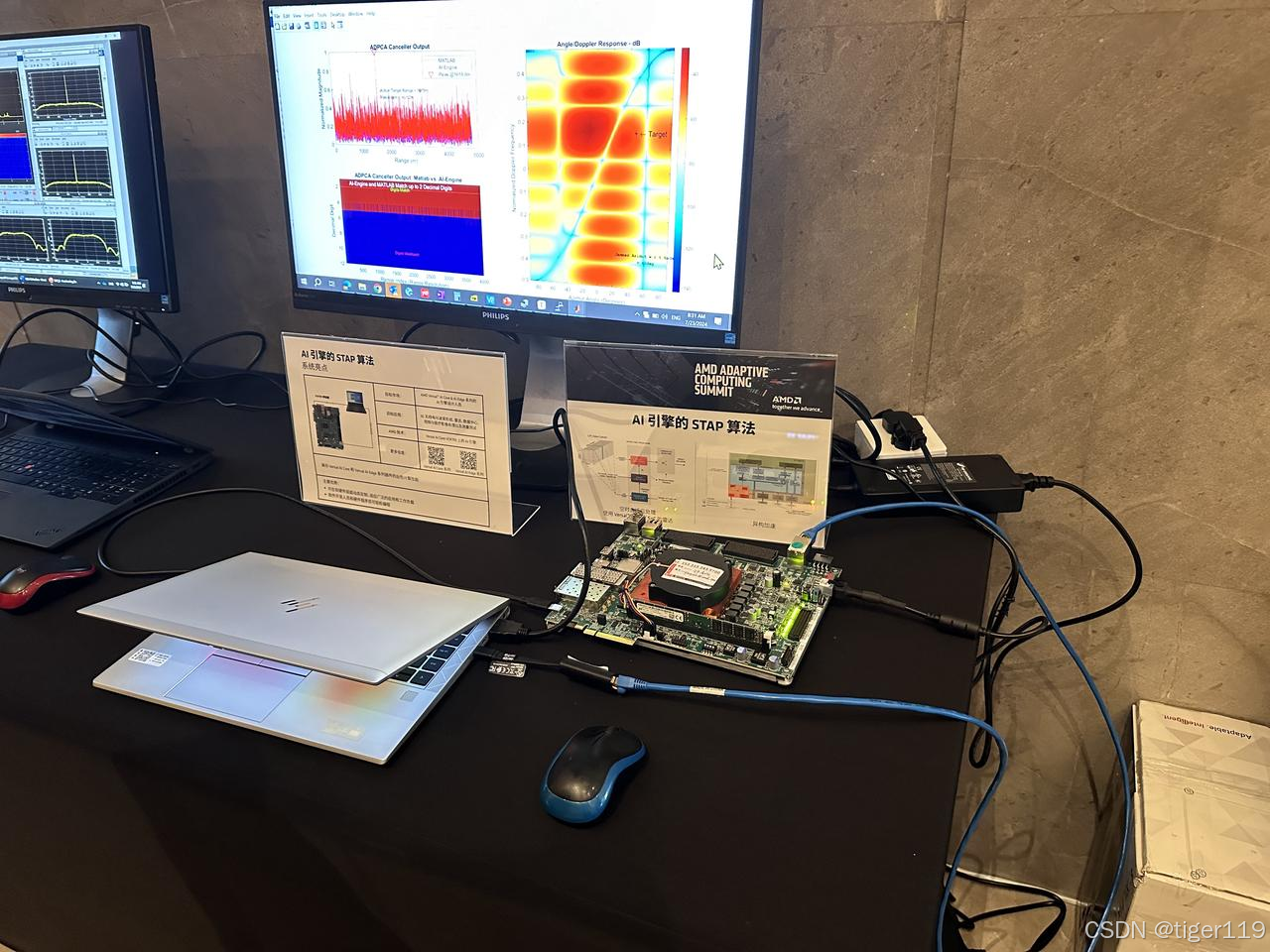
STAP算法,全称Space-Time (时空自适应处理),是一种信号处理技术,广泛应用于雷达、声纳和通信系统中,尤其是在抗干扰和目标检测方面。它结合了空域和时域的信号处理,能够有效地提高信号的信噪比(SNR),从而更好地检测和分辨目标。
STAP涉及大量的多维数据处理,需要进行复杂的矩阵运算。雷达需要低延时。AIE比较擅长DSP可以完成的运算。
采用 AI Core ,大量使用 AIE。
3.1.3:Vitis Model 助力加速开发: 和 中基于模型的设计
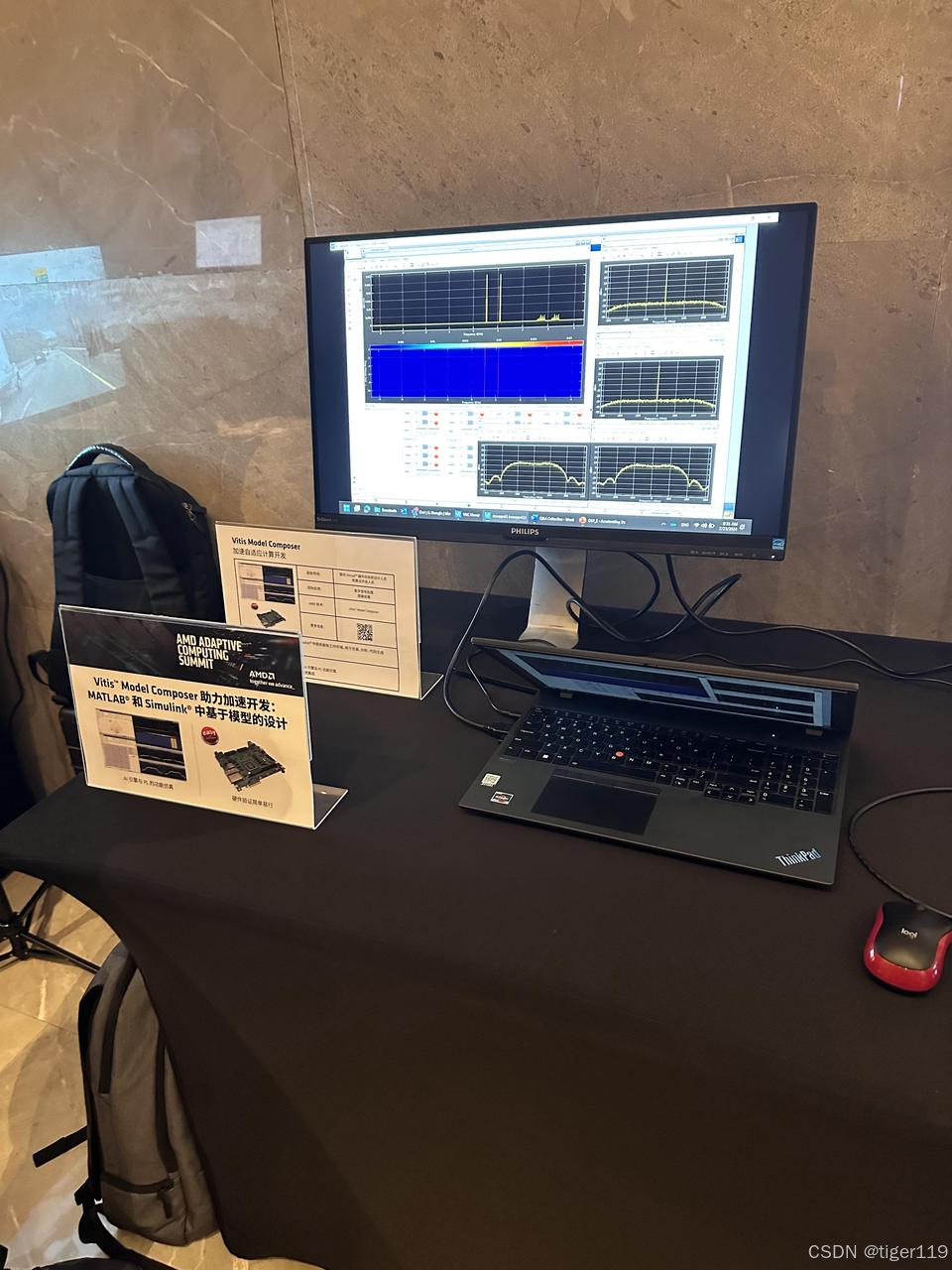
将Vitis Model 集成在和环境中,利用图形化界面和仿真功能进行硬件设计。
3.1.4: AI 引擎-ML推理

Vitis AI 支持的 Model 不多,很多通用模型都不支持。支持的模型大都需要AIE-ML 版本的芯片。
感觉在这块儿,AMD没怎么维护和发展。在后面的演讲中,问过AMD专家,感觉AMD基本已经放弃原来在AI上的通用战略,在推理上也基本完全无法与Nvida抗衡。
3.1.5:AMD V RSIC-V 处理器TMR演示

用这个软核可以在小批量场景使用,TMR是在军事/航天等对安全,可靠性要求高的场景。

3.1.6:AMD采用Info封装的成本优化型解决方案

TSMC( Fan-Out) 提供的先进的封装技术,可以实现与外界高密度互联,封装更簿,传输性能更好,散热性更好。没有基板,更小的封装尺寸。
3.1.7: HB 性能监控器

应用在HPC,机器学习,通信场景,实时监控和管理 HB 平台的性能。
3.1.8:AMD AI Core : PL 电源管理

AMD AI Core 开发板中的 PL 电源管理系统通过一系列优化策略和工具,提供了高效、灵活的电源管理解决方案。无论是高性能计算、人工智能应用,还是嵌入式系统,PL 电源管理都能帮助开发者优化系统性能、降低功耗、提高可靠性和延长设备寿命。通过合理使用动态电压和频率调节、部分重配置、电源域划分和时钟门控等技术, 开发板在实现高性能计算的同时,也实现了能效优化。
3.1.9: 可编程片上网络(NoC)的RTL

如何针对NoC进行RTL编程
3.1.10:Vitis IDE 嵌入式开发

Vitis提供了统一的开发IDE,这个其实去年就有了。
3.1.11:Arm Mail GPU: 为在 AMD Kria SOM经过认证的上执行图形渲染提供支持。

Arm Mali GPU 在 AMD Kria SOM 上运行,并且这些模块已经通过认证,可以运行 操作系统。这种组合为嵌入式系统中的图形渲染任务提供了支持。一种组合解决方案。
3.2:合作伙伴展台 3.2.1:芯驿电子科技
Alinx 是一家车载智能产品和FPGA技术方案公司,专注于车载智能产品,FPGA产品方案定制。

FPGA + GPU 异架构,实现高清高速,AI边缘计算处理诊断,手术辅助。
医疗核心板: AI Edge ,AMD Zynq,AMD Zynq + MPSoC,
另外,也有紫光同创核心板。
内窥镜处理:图像增强(比如:提高分辨率和清晰度),图像压缩传输(方便快速传输),确定低延时,高质量的图像传输。
手术机器人:运动控制算法,传感器的数据并行预处理。
主要针对目标检测模型的卷积神经网络的实现。
是一个Linux工作站,Intel 至强CPU,16G DDR4,1TB SSD存储,双卡GPU,PCIe插槽。FPGA主要还是完成数据的传输,协议转换,数据压缩。

汽车电子后视镜CMS解决方案。图像处理,解决时间延迟的问题。
3.2.2:思尔芯
一家数字EDA供应商,为客户提供架构设计,软硬件仿真,原型验证,数字调试,EDA云等工具及服务。
基于AMD VU7SP,原型验证系统。支持 4,900万门的ASIC设计

3.2.3:北格逻辑
一家专业的FPGA应用加速方案提供商,IC前端设计服务商。
提供浅压缩解决方案。

3.2.4:玄武科技
聚焦于FPGA及SoC的计算,网络,存储及数据采集,提供高性能高可靠的板卡级方案和数据中心互联的产品。致力于AI高性能计算硬件平台与数字底座的供应商。

3.2.5:安富利
AMD全球授权分销商。

集成了AI技术的传感器解决方案。
3.2.6:科通
知名的芯片应用设计和分销服务商,是AMD中国大陆地区授权分销商。
提供设计服务——电路器件选型,原理图/版图设计,物流支持。
形成工业平台整体方案,医疗平台整体方案。

4:主题演讲 4.1:AMD 官方演讲 4.1.1:整体介绍(合并后的整合)
讲解 与AMD 合并的历史。介绍重点产品:DPU &
合并后关注 CPU,GPU,FPGA 如何协同,实际上将AIE技术应用到了CPU,半放弃了AI在FPGA中的应用。AIE 过渡到 AMD 。
更加关注与TSMC合作(芯片工艺)
4.1.2:产品讲解

10个不同的行业:
低价/高效系列+系列(将云端迁到边缘)
Soc:HBM,,AI Edge,
低功耗/低成本 系列 & AMD Zynq :
Vitis AI的使用

展示了AMD统一AI堆栈的整体架构,涵盖了从模型优化、开发工具到运行时环境的完整生态系统。它支持多种AI框架(如、)、统一的开发和部署工具(如ONNX 、Vitis AI)、以及通用的编译器和库API。该堆栈还依托于ROCm平台,提供强大的硬件支持,包括AMD的CPU、GPU和自适应SoC(和Zynq)。通过这些工具和平台,开发者能够高效地开发、优化和部署AI模型,实现无缝的工作负载分区和高性能推理。AMD AI Stack提供了一个全面的、优化的AI开发和部署平台,适用于各种AI应用场景,简化了从开发到部署的整个流程。
4.1.3:技术演讲

介绍AMD在AI领域的应用以及解决方案:
商业和企业:AMD EPYC,Ryzen Pro CPU。
智能工厂/智能零售/自驾/智慧城市/通信/:机器视觉,使用 和 SoC
数字家庭:CPU,GPU,,SoC
生命科学:SoC,生物分析,药物研发,医疗诊断
云数据中心:AMD EPYC 处理器,FPGA,GPU,AI推理,训练,自动化,数据处理……

AI驱动的三阶段:
一阶段:数据预处理——使用FPGA进行数据融合,针对各种传感器数据。
二阶段:AI推理——使用AI 执行深度学习和机器学习算法。
三阶段:后处理——使用CPU,完成控制和决策逻辑。

客户最关注——连接(传感器,物联网设备,通信设备),边缘智能,运算(AI和高级运算),高密集/高带宽.

二代架构——重点突出了在计算性能、安全性、连接性、内存带宽、AI能力、视频处理和图形处理等方面的显著提升。这些改进使得系列SoCs在处理复杂计算任务、实现高级图像和视频处理以及提供高效AI推理方面具备更强的能力,适用于多种高性能和关键任务应用场景。
4.2:合作商演讲 4.2.1:芯驿电子科技
Alinx——FPGA的开发板,SOM板,
AUMO——车载电子产品设计
提供仿真平台

4.2.2:北格逻辑
的编解码——



4.2.3:玄武科技


4.2.4:思尔芯
国产EDA,数字前端布局。主要是芯片验证。
加速超大规模芯片开发。

5:分会场演讲 5.1:AI引擎概述和架构基础
问题:对于AIE要做深度学习,比如要实现的架构,发现不支持架构的模型。
但是在Ryzen的AIE确是可以的。
上实现是不可以的,但是在AMD 的CPU上是可以的。为什么?
AIE 底层来说还是 DSP,提供了库函数。AIE 兼顾了数字处理和
深度学习,也就是将模型拆解出来,然后直接提供底层的算子。
PL 的 和 AIE的编译,两者不相关,没有时序的问题。
可以使用HLS来进行开发。PL才会有时序问题。

AMD在AI引擎优化方面的不同策略。AIE适用于一般的AI推理任务,而AIE-ML则针对机器学习和深度学习任务进行了特别优化,提供更高的计算能力和效率。
实际上AIE只能使用C++编码,自行编写算法。门槛很高。AIE-ML可以使用Vitis-AI,基于模型编程。

使用适应性数据流图(ADF)和AI引擎内核为DSP应用进行编程。通过使用C/C++编写内核函数,定义输入输出绑定,并通过编译优化在AI引擎上运行多个内核,可以实现高效的信号处理和数据处理。AI引擎结合可编程逻辑(PL),提供了强大的计算能力和灵活性,适用于各种复杂的DSP应用。

AMD的AI引擎架构在高性能DSP应用中具有显著优势:
信号处理,机器学习,嵌入式系统,
5.2:常用DSP功能的AI引擎基准测试:FIR,FFT和通用短阵乘法(GeMM)

FIR(有限脉冲响应滤波器)和FFT(快速傅里叶变换)基准测试:

AI引擎在高性能DSP(数字信号处理)功能中的优势:
AI引擎在高性能DSP功能中的优势
AIE在高性能DSP功能(如FIR和FFT)中能够带来资源和动态功耗方面的优势。使用AI引擎可以更高效地利用硬件资源,并降低运行过程中的动态功耗,从而提升整体性能和能效。
AI引擎在特定数据类型中的最佳表现
AIE在处理16位和32位数据类型时表现最佳。对于这些常见的数据类型,AI引擎经过优化能够提供最佳的性能表现和处理效率。
高点FFT的优化架构
对于高点FFT,最优的架构是AI引擎和可编程逻辑的结合。在处理复杂的高点FFT时,将AI引擎和可编程逻辑结合使用,可以充分发挥两者的优势,实现更高效的计算和资源利用。
5.3: with AIE

AIE-DSP设计流程的各个步骤:
映射系统功能(Map the into )
将系统功能映射到将在AIE(AI引擎)和PL(可编程逻辑)中实现的功能。这一步骤涉及确定哪些功能将在AIE中实现,哪些功能将在PL中实现,以便有效利用两者的优势。
实现功能( the )
在AIE Tile Array中实现功能,使用库函数、AIE API和内在编码( )的组合。使用可用的库和API来编写和实现具体的功能,确保这些功能可以在AIE的计算单元上高效运行。
实例化和互连( and )
实例化并互连多个AIE tiles,使用图形化代码(GRAPH-C code)。将多个AIE计算单元实例化并互连,形成一个完整的计算网络,确保各个单元之间的数据流通顺畅。
编译和仿真( & )
编译和仿真AIE和AIE+PL的设计。编译整个设计,并进行仿真,以验证设计的功能和性能,确保其满足预期的要求。
5.4: AIE into .

包含AI引擎的AMD ™系统的架构,平台部分和AI引擎与可编程逻辑子系统的组成和开发流程。通过使用AMD的™ Suite和Vitis™软件平台,硬件团队和算法团队可以分别开发和优化系统的基础硬件和AI计算功能,从而实现高效、灵活和可扩展的计算平台,满足各种高性能应用的需求。

利用PL可编程+AIE来结合实现。
5.5: with Vitis Model

开发步骤:
1:使用进行设计。
2:使用仿真工具进行功能验证。
3:分析找出潜在问题,进行优化。
4:在硬件上验证。
5:最终导出,装备生产和进一步开发。
大概整理了一下资料,如上。