时间:2025-01-17 来源:FPGA_UCY 关于我们 0
今天和大家聊一聊FPGA在人工智能时代特有的优势,由于我的工作性质,我也需要不断的了解这块的知识呃,并且分享给大家和大家一起学习。我们每天都在用手机,电脑发送信息和数据,那我们有没有想过这个人工智能时代,谁在发挥独特的优势呢?
那就不得不说芯片内部源于沙子的复杂体系,我们可以叫做建筑结构。其中道格.伯格尔就是这个伟大的建筑师的一员。也是现任微软技术院士,曾任德克萨斯大学奥斯丁分校的教授。
也是微软FPGA项目的首席架构师和主要负责人。
两年前,博格尔在微软研究院博客中分享了他对后摩尔定律时代芯片产业发展的观点和愿景。也展望了人工智能时代芯片技术的前进方向。
像微软这样的软件互联网公司为什么也要进军芯片行业,以及在微软眼中,什么才是FPGA在人工智能时代的独特优势。
今天我们可以谈谈这么几个内容。
首先,什么是所谓的暗硅效应,另外相对于CPU和GPU而言,FPGA这种芯片到底有哪些特殊之处。那我们可以讲讲来自微软的FPGA的两个主要项目, 和 。最后我们在分析一下人工智能芯片发展路在什么方向。
什么是暗硅效应?
大约十几年前,学术界和工业界的主要发展趋势就是多核心架构,虽然当时没有成为全球共识,但在当时多核架构是非常热门的研究方向。
人们认为可以如果可以找到编写和运行并行软件的方法,我们就可以将处理器架构扩展到数千个核心。 然而当时任德州大学奥斯汀分校教授的伯格尔却对此不以为然 于是他在2011年发表了一篇论文提出所谓的暗硅效应,而这项研究也深深影响了整个芯片行业接下来的发展轨迹,那么什么是暗硅效应呢,暗硅效应就是虽然我们能不断的增加处理器核心的数量,但是由于能耗的限制,我们却无法让他们同时工作。这就好像移动大楼里有很多房间,但由于能耗限制,你无法同时开启所有大楼里的所有灯光,这样就使得这栋大楼里,在夜晚有很多看起来黑暗的部分。
而这就是暗硅得名的原因。
暗硅效应的本质是在后摩尔定律时代,晶体管的能效发展已经趋于停滞,这样即使人们开发出并行软件,并且不断增加核心的数量,所带来的性能的提升也非常的有限。所以业界还需要在其他方面带来更多的进展,以客服暗硅效应带来的问题。
如何应对暗硅效应?
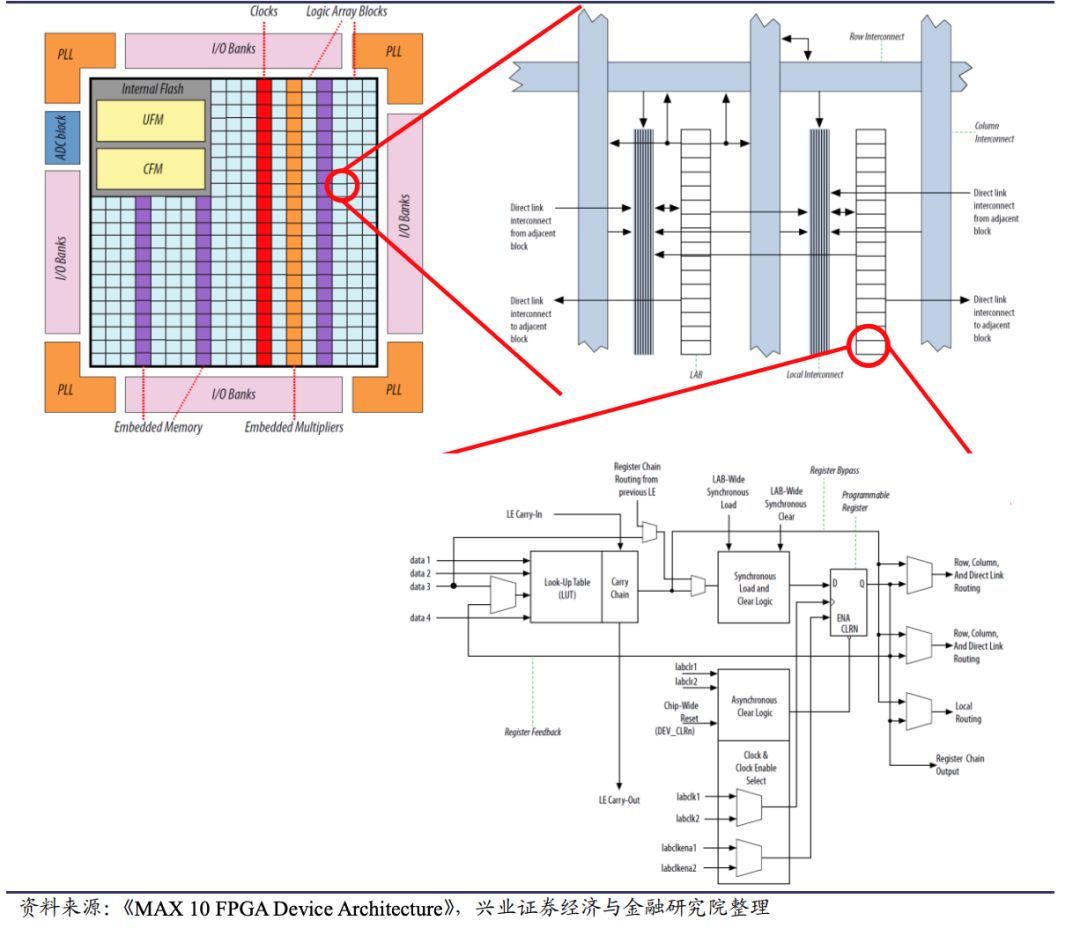
很明显,传统的多核架构无法应对暗硅效应带来的功耗难题。那么有一个可行的解决方案,就是采用定制计算的方法。 也就是说,为特定的工作场景和负载优化硬件设计,比如不使用通用的处理器,为应用场景优化计算结构,嗯,使用领域专用的一些处理器,嗯,这样能够达到高性能,低功耗的效果,然而,设计和制造定制芯片的最主要的问题就是高昂的成本,例如,对一个复杂的云计算场景,不论是使用者还是设计者,都不会采用一个由成千上万种不同芯片组成的复杂系统,因此,人们的视线集中到了一个名为FPGA的芯片上,FPGA全名叫做现场可编程门阵列,它的本质是一个可编程的芯片,人们可以把硬件设计重复烧写在她它的可编程存储器上,从而使FPGA可以执行不同的硬件设计和逻辑功能,另外,你也可以在使用现场动态的改变他上面的进行结构,这也就是为什么它被称为现场可编程的原因,事实上,你可以每隔几秒钟就改变一次FPGA上面运行的硬件设计,因此,这种芯片非常的灵活,基于这些特点,很多公司开始布局FPGA技术。这其中不乏微软,亚马逊,腾讯阿里等互联网与软件公司。
例如,微软就将FPGA广泛的部署到了他们的云数据中心里,与此同时,他们也开始将很多重要的应用和功能,从其软件的实现方式,慢慢的转移到了基于FPGA的硬件实现方式上,可以说这是非常有趣的计算架构,他也成为了微软基于定制化硬件的通用计算平台,Fpj的重要特点是什么呢?那么就是它的灵活性,例如,如果具体的应用场景或者算法发展的太快, 或者硬件规模太小的时候,我们就可以使用FPGA用硬件来实现这些功能,当应用规模逐渐扩大时,我们就可以在合适的时间选择将这些已经成熟的硬件功能或者设计转化成定制化的芯片,以提高他们的稳定性和降低功耗和成本,我们要知道,FPGA芯片并不是一个全新的物种,事实上,目前FPGA已经在电信领域得到了非常广泛的应用,这种芯片非常擅长于对数据流进行快速的处理,同时,也被应用于流片前的功能测试等等,这些我们以后可以慢慢去说去了解。
FPGA 和CPU和GPU
CPU和GPU都是令人惊叹的计算机架构。
他们是为了不同的工作场景和应用负载而设计。
拿CPU来说,它是一种非常通用的架构,它的工作方式基于一系列的计算机指令,也称为指令集,简单来说,CPU从内存中提取一小部分数据,放在寄存器或者缓存中,然后使用一系列指令对这些数据进行操作,等操作完毕后,将数据再写回内存,提取另外一小部分数据,再用指令进行操作,周而复始,不过,如果这些需要使用指令进行处理的数据集太大,或者数据值太大的话,那么CPU就不能很好的处理这种情况了?这也就是为什么在处理高速网络流量的时候,我们往往需要定制芯片,比如网卡芯片,而不是CPU,这是因为在CPU中,即使处理一个字节的数据,也要使用一堆的指令才能完成,而当数据流非常大,以每秒125艾字节流入系统时,这种处理方式,哪怕使用再多的线程也忙不过来。
那么,对于GPU来说。他所擅长的是被称作单指令多数据流的并行处理,这种处理方式的本质在GPU中有着一堆相同的计算核心,可以处理类似但并不完全相同的数据,因此,可以使用一条指令,就让这些计算核心执行相同的操作,并且并行的处理所有的数据,最后,对于FPGA而言,它实际上是CPU计算模型中的“转置”,在CPU中,数据即被锁定在架构上,然后使用一条条指令对其处理,FPGA则是将指令锁定在架构上,然后在上面运行数据流。FPGA这种计算方式的核心思想是什么呢?就是将某种计算架构用硬件电路实现出来,然后持续地将数据流输入系统并完成计算,在云计算中,这种架构对于高速传输的网络数据流非常有效,并且对CPU来说也是一个非常好的补充。
微软项目。
微软项目的主要目的是在微软的云数据中心中大规模部署FPGA,虽然这个项目涵盖了电路和系统的架构设计懂工程实践,但它的本质仍然是一个研究项目,在这之前,并没有公司能够真正成功的对FPGA在云数据中心里进行工业化的部署,从2015年末开始,微软在购买新服务器时,几乎都会在上面布置FPGA板卡,这些服务器被用于微软的必应搜索,Azure云服务以及其他的各种应用。到目前为止,微软已经在遍布世界各地的数据中心里部署FPGA,并且已经发展到了非常大的规模,这也使得微软成为了世界上最大的FPGA客户之一,在微软内部。很多团队都在使用kite ph f增强自己的服务,比如FPGA可以对云计算的诸多网络功能,进行计算加速,这样就能为客户提供比以往更加快速,安全,稳定的云计算和网络服务,当网络数据包以每秒500亿比特速度进行传输时,我们可以使用FPGA对这些数据包进行控制分类和改写,相反的,如果使用CPU来实现这些功能的话,将需要海量的CPU内核资源,因此,对于这样的应用场景,显然,FPGA是一个更好的选择。
好啵,项目与实时AI
当前,人工智能有了很大的发展,而且在很大程度上归功于深度学习技术的发展,人们逐渐意识到,当你有了深度学习的算法模型,并构建了深度神经网络时,需要足够多的数据去训练网络,只有加入更多的数据,才会让深度神经网络变得,更大更好,通过使用深度学习,我们在很多传统的AR领域取得了长足的进展,比如机器翻译,语音识别,计算机视觉等等,同时,深度学习也可以逐步替代这些领域发展的多年专用算法。这些巨大的发展和变革,促使业界思考他们对,芯片架构和计算模式的影响,哦,再以微软为例,他们开始重点布局对AI机器学习,特别是深度学习的定制化硬件架构,这也是脑波项目产生的主要背景,脑波项目提出了一种深度神经网络处理器,也有人称之为神经处理单元或者npu,毕竟搜索这样的应用,需要很强的算力,这是因为只有不断的学习和训练,才能向用户,提供更优的搜索结果,因此,微软将大型的深度神经网络利用FPGA,进行加速并取得了很好的结果,目前,这种计算架构已经在全球范围内运行了一段时间,微软在2018年的开发者大会上正式发布了,脑波项目在Azure云服务的预览版。他们也为用户提供带有FPGA的板卡,使用户可以使用自己公司的服务器,从Azure上获取AI模型并运行。
那么,什么是评价实施AI的主要标准呢?
这里面主要的性能指标之一就是延时的大小,然而,延时究竟多小才够小?似乎是一个哲学问题,这事实上,取决于具体的应用场景,比如,如果在网络上监控并接收多个信号,并从中分析哪个地方发生了异常情况?那么几分钟的时间,可能就足够了,然而,如果你正在和某人通过网络进行交谈,哪怕是非常小的延时和卡顿,也会影响通话质量,就像很多电视直播采访里经常出现的两个人在,同时,讲话的情景,很多情况下,增加系统的处理速度,势必会带来更多的投入和成本的攀升,两者很难同时满足,但这就是脑波项目的主要优势所在,或使用FPGA,我们在这两个方面可以达到很好的平衡,也就是说,我们既可以得到很高的性能,也会有令人满意的成本和功耗。