时间:2024-08-03 来源:网络搜集 关于我们 0
作者:Chris Brooks(Head of Science Innovation @dunnhumby)
编译:Aderf
原文:
https://medium.com/dunnhumby-data-science-engineering/accelerating-machine-learning-with-fpgas-ab4db1ad611a加速机器学习模型变得越来越重要。可重新编程的硬件,如FPGA(Field-Programmable Gate Array),即现场可编程门阵列,可能是模型性能下一步变化的关键。
在过去的18个月里,dunnhumby与伦敦帝国理工学院高性能嵌入式和分布式系统的EPSRC培训中心合作,一直在研究可重新编程的硬件,结果我们发现了一种独特的方法,下文将详细说明。
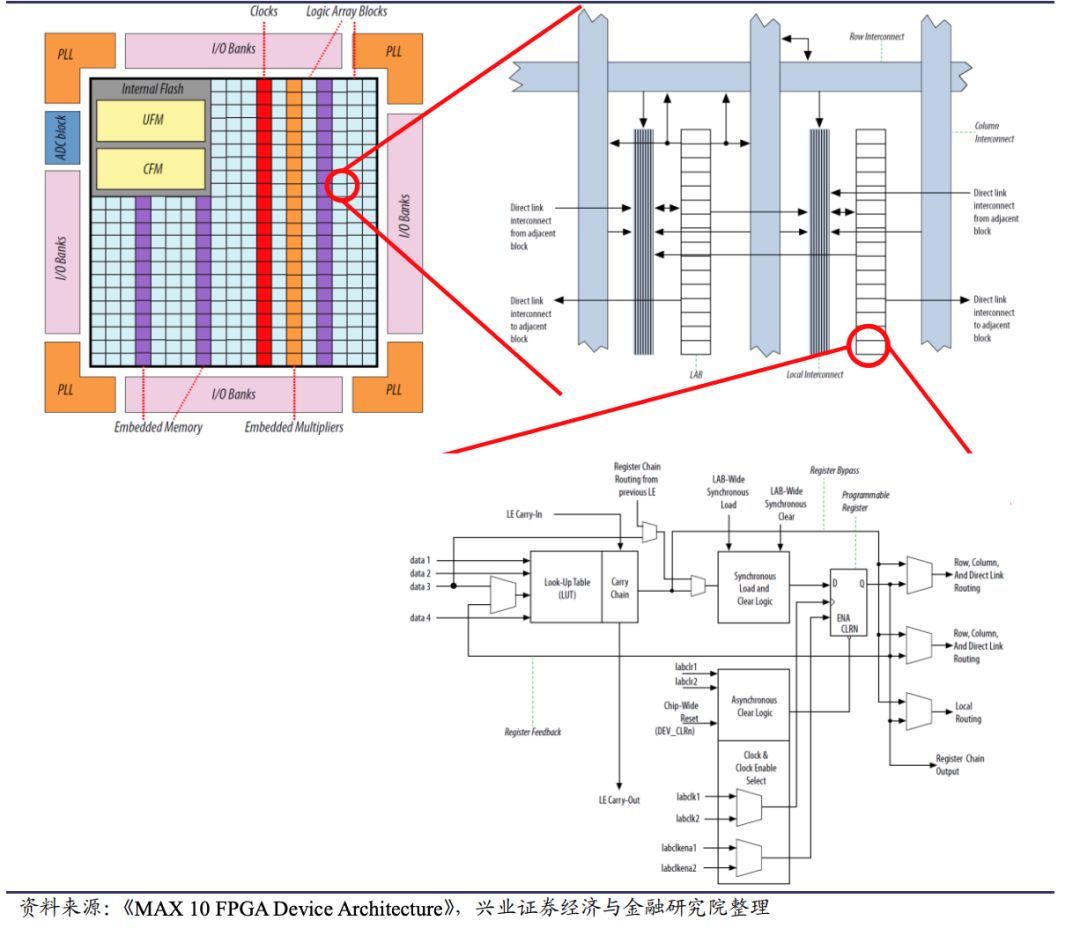
现场可编程门阵列(FPGA),一种可重新编程的硬件
大多数硬件不可重新编程,因为硬件逻辑在制造时是固定的,所以必须通过改变软件,例如计算机程序,以便改变执行的逻辑。不可重新编程的硬件包括:
中央处理器(CPU ):计算机和移动设备背后的核心大脑。 图形处理器(GPU):主要用于高级图形,但也可用于大规模并发计算。相比之下,可重新编程硬件中的硬件逻辑不是固定的,可以由用户更新。我们的研究使用了一种称为现场可编程门阵列(简称FPGA)的可重新编程硬件,以了解它们对某些类型的计算是否可以比CPU和GPU更快,因为FPGA能够自定义硬件逻辑执行需要的工作。
我们知道FPGA并不总是比其他类型的硬件更快,因此研究的一个关键部分是确定FPGA在哪些方面比CPU和GPU更快。我们还需要考虑成本和复杂性。使用FPGA比CPU或GPU更复杂,但这可以通过更好的性能和吞吐量来抵消。
由于可重新编程的硬件涉及深厚的技术知识,我们与该领域的专家,伦敦帝国理工学院合作,并赞助了2017年9月开始的博士学位。
我们很快就了解到FPGA的工作特别适用于可以并行化和流水线化的逻辑:
并行逻辑 可以同时发生而不依赖于彼此的步骤。例如。如果X个工作单元可以同时发生,那么吞吐量是每个周期的X个工作单位。 流水线逻辑 可以一个接一个地发生的一系列步骤,这些步骤不依赖于序列中的其他步骤。即从后续步骤到序列中的前一步骤没有反馈。相反,如果在一个过程的5个步骤之后存在反馈回路,则吞吐量减少了5倍,因为序列中的先前步骤必须等待。 例如,并行排序网络具有高吞吐量,因为它既是并行化的又是流水线的。分拣网络具有高吞吐量,因为其逻辑是并行和流水线的
我们的研究已经发现了一种新的分拣技术,该技术经过同行评审,并于2018年12月在日本冲绳的国际现场可编程技术会议上发表。
该方法是一种快速,轻量级的并行排序算法,称为FLiMS。它通过显著减少流程长度改进了之前的最佳方法,从而改善了延迟并有效地使用了硬件。有关FLiMS的更多详细信息,请阅读此处的全文(
https://ieeexplore.ieee.org/document/8742328?source=
post_page---------------------------)。关于使用可重新编程硬件的FLiMS排序算法,经同行评审论文
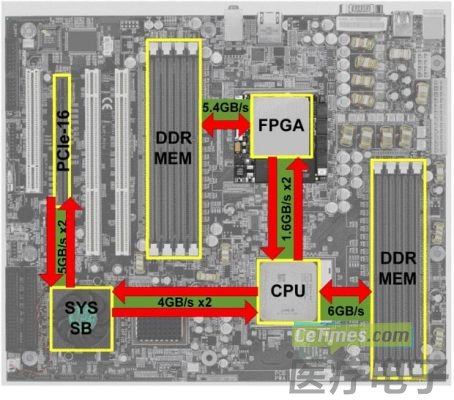
我们现在关注的是可重新编程的硬件如何能够用于构建机器学习模型。我们的重点是distinct counting,一种计算成本高得惊人的通用指标,让它按照用户要求的速度交付结果。
更快的查询带来许多好处,包括更高效的硬件利用率和更好的用户体验。我们还在考虑如何在生产中使用FPGA。越来越多的云提供商正在提供FPGA实例,这为加速机器学习的未来开辟了令人兴奋的可能性。
关注公众号邓韩贝dunnhumby(ID: dunnhumby-China)即时获取最新信息。