时间:2024-08-01 来源:网络搜集 关于我们 0
导读 全文目录:
1. 前言
2. 图结构构建
3. 可扩展性
4.鲁棒性
5. AutoGL库和GNAS评估
6. Q&A
分享嘉宾|张子威 清华大学 博士后
编辑整理|张兰兰
内容校对|李瑶
出品社区|DataFun
01
前言
许多复杂系统具有图的形式,如社交网络、生物网络和信息网络。图数据具有不同的形态和种类,例如社交网络非常大,具有几十亿的节点和边,而生物的分子网络数量多,但每个分子的网络较小,因此图的形态多样性为图机器学习带来了挑战。
图神经网络(GNN)是目前图分析的主流学习范式,消息传递的图神经网络是使用最广泛的架构。消息传递范式是一种聚合邻居节点表征来更新中心节点表征的过程,它将卷积算子推广到不规则数据领域,实现了图与神经网络的连接。
传统图机器学习存在两方面的局限性,一方面是图神经网络的参数和架构设计,通过人类经验进行反复调整,试错过程消耗了大量人力成本,另一方面是每个图任务和数据都是单独处理,例如十个图数据需要设计十个图模型。自动机器学习(AutoML)为解决图机器学习的自适应性提供了思路,工作重点从设计图的机器学习方法转为了设计图的自动机器学习方法。
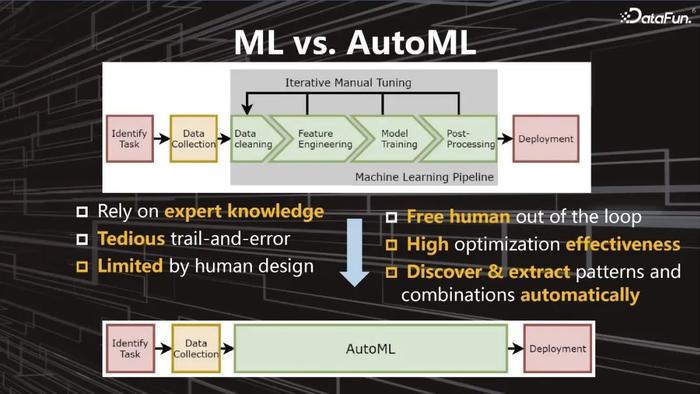 图1:流程对比
图1:流程对比图1显示AutoML将传统机器学习中人工部分替换为自动化过程,例如数据清洗、特征工程、模型设计等,减少对专家知识的依赖和人工反复调参,从而实现自动的、更高效的优化。
图神经架构搜索(Graph Neural Architecture Search, Graph NAS)是目前研究和应用值得关注的方向,首先介绍一下神经架构搜索(NAS)的概念,它自动化学习得到最优的神经网络架构,主要由搜索空间、搜索策略、性能评估策略三部分组成,搜索空间是可选择神经网络架构的集合,搜索策略决定了架构的选择过程,性能评估策略则用于判断架构的优劣,如下图2所示。NAS方法,简而言之,即给定一个搜索空间,使用某种搜索策略得出最优神经网络架构,同时通过性能评估策略判定网络架构的优劣。搜索空间随着深度学习架构的演进也在不断提升,启发于架构由重复的基本模式组成,搜索对象由整个架构转为细胞(cell)或块(block),产生基于cell的搜索空间,同时对应产生一种可设计的选择方法用于宏观架构和微观架构;搜索策略为了选择适合架构得到高精度验证结果,包含随机选择、Bayesian 优化、进化算法、强化学习(RL)和 基于梯度的方法;性能评估策略解决不能穷举似的训练每个架构产生资源花费高的问题,例如共享参数或使用父模型权重。
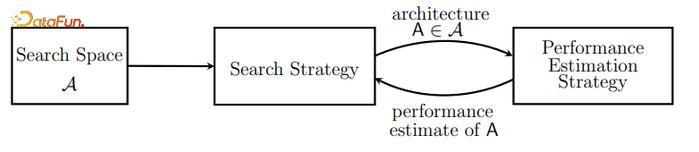 图2:NAS方法组成元素
图2:NAS方法组成元素基于NAS的搜索算法在设计CNN和RNN的新架构方面取得了很好的效果,将NAS扩展到设计GNN的图神经架构,从而开展Graph NAS研究。
作者及其团队对自动图机器学习概况进行了调研,可参考其论文:Automated Machine Learning on Graphs: A Survey. IJCAI, 2021. 针对AutoML算法的超参数优化hyper-parameter optimization (HPO)和神经架构搜索这两方面来分析图的自动机器学习研究,HPO应用在图机器学习的主要挑战是可扩展性,NAS应用在图机器学习时主要考虑搜索空间、搜索策略和性能评估策略三方面对GNN的适应性调整,具体如下:
1)Graph NAS的搜索空间有四类:微观搜索空间Micro Search Space、宏观搜索空间Macro Search Space、池化搜索空间Pooling Methods和超参数Hyper-parameters,图的任务分为节点级和图级,不同图任务可能需要不同的搜索空间,图架构在不同数据集和任务上不一定具有可迁移性,一个适合的搜索空间需要精心的设计和领域知识。
2)搜索策略可以直接使用NAS常用的搜索策略,有三个种类:一是强化学习,通过控制器生成图神经网络的架构,设计强化学习奖励函数来训练架构,反复迭代后得到所需架构;二是利用进化算法,定义图神经网络中不同算子之间如何演化和如何选择,使用已有的演化算法来优化;三是可微分方式,目前最受关注,使得Graph NAS的效率得到很大提升,其将所有可能的算子融合成为一个超网络Supernet,通过端到端的可微分方式进行学习。此外也可以将三种搜索策略联合起来使用。
3)性能评估策略,一方面是可以降低保真的程度,例如减少训练轮数(epoch),这些方法可以直接推广到GNN,另一方面是类似CNN在不同模型使用共享方式,例如共享参数、共享权重,扩展到GNN有难度但具有研究价值。
早期Graph NAS的研究虽然取得了一定进展,但仍然面临三方面的挑战,一是图结构,区别于图像、文本和语音,图的表征和图任务相对复杂和多样,图结构需要特别处理;二是可扩展性,由于大规模图在日常中非常常见,如何使Graph NAS应用到大规模图,解决计算性能问题;三是鲁棒性,类似图像的鲁棒性,图的鲁棒性在风险敏感领域带来很大挑战,例如金融、医疗。
接下来将介绍作者团队针对这三方面挑战提出的对应解决办法和发表的相关论文,并介绍其团队已经开源的图自动机器学习库AutoGL,以及Graph NAS评测方法。
02
图结构构建
图结构(graph structure)是Graph NAS中最核心的一个因素,也是图神经架构搜索区别于传统神经架构搜索的核心。但之前的大部分研究假设图的结构是固定的,难以回答以下两个问题:
Q1:输入的图结构是否是最优的?例如从社交网络或金融网络中获取了图结构数据,能否判定数据中的图结构对下游任务为最优是没有定论的。
Q2:如何联合建模搜索空间中GNN架构和图结构,使之最为匹配,实现最优图结构和最佳图架构。
总而言之,面临的挑战是如何在Graph NAS中建模不同的图结构。经数学证明和模拟数据集验证发现,不同图结构所需图神经网络算子也不同。如图3所示,直观来说,若使用信噪比来衡量图结构的信息,左边的图结构比右边包含更多信息,两者需要的图算子也是不一样的。
 图3:图结构对比
图3:图结构对比基于上述发现,作者及其团队提出GASSO(Graph Architecture Search with Structure Optimization)算法,详见论文:Graph Differentiable Architecture Search with Structure Learning. NeurIPS, 2021. 算法联合学习图结构和图神经网络架构,通过联合优化的方式找到最适合彼此的组合对,如图4所示,上半部分为图结构,下半部分为神经网络架构,经过联合优化过程对图结构和GNN架构的反馈使得联合学习满足目标要求。
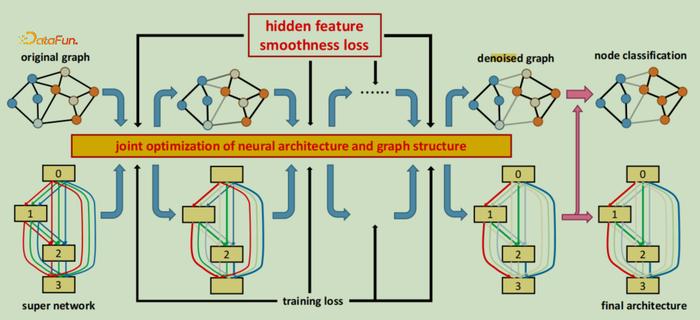 图4:GASSO模型
图4:GASSO模型联合优化有三方面内容:
一是图结构可微分,图结构的离散空间特性使得离散的图结构优化困难,通过使边可微分解决这个问题;
二是根据图中的同质性假设(Homophily)与一阶相似度(first-order proximity)假设,即相似特征的节点形成边连接的概率更大,将节点的隐层表征近似为节点标签,并通过节点特征平滑度损失和与初始图结构的距离损失作为优化的正则项;
三是传统Graph NAS从数学表达公式来看被抽象为双层优化问题,外层是GNN架构A进行优化,内层是对GNN参数W进行优化,GASSO模型将之扩展成为三层优化,外层还是架构优化,内层是参数优化,但在两者之间添加了图结构的优化G,如图5所示。
 图5:GASSO模型的数学表达式
图5:GASSO模型的数学表达式具体实现时,GASSO使用边的掩码(mask)获取优化后的图结构,可以有效消除给定边中的噪声。但是这个方法存在的潜在问题是不能使图中新增边。一个主要挑战是如果考虑任意节点对都可能形成边,计算复杂度为节点的平方,大规模图无法接受这样的复杂度,因此使GASSO模型不但具有删边能力同时可以新增边是我们正在进行的一个工作。
从实验结果来看,在图的基准数据集和大规模图数据集上,GASSO模型效果最优。
GASSO关注在静态同构图,而动态异构图在实际应用中更加普遍,如引用网络和金融中交易网络,“动态”是指图的结构和特征随时间演化,例如交易数据每天都在不断变化,“异构”是指图的节点和边有多种类型,例如金融网络的节点包含客户、银行、企业等,边代表的业务场景随经济活动而定义。动态异构图比静态同构图会更加复杂,如何在Graph NAS中建模图的动态性和异构性是一个重要挑战,详见作者及其团队论文:Dynamic Heterogeneous Graph Attention Neural Architecture Search. AAAI, 2023. 论文中核心思想是使用注意力机制对不同的时间、不同类型的节点和边进行自动化建模,主要解决两方面的问题:一是如何设计搜索空间,共同考虑图中的时空依赖性和异构交互作用;二是如何在潜在的大而复杂的搜索空间中设计一个有效的搜索算法。模型框架如下图6所示。
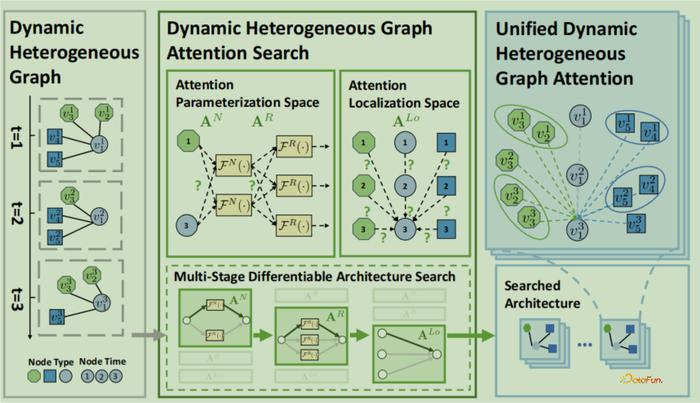 图6:Dynamic Heterogeneous Graph Attention Search (DHGAS) 模型框架
图6:Dynamic Heterogeneous Graph Attention Search (DHGAS) 模型框架图6的左边给定三个时刻、三种类型的5个节点图结构的示意图,展示动态异构图特性,中间DHGAS包含三部分内容:参数化空间的注意力机制、定位空间的注意力机制和多阶段可微分架构搜索策略,右边代表统一的动态异构图注意力机制框架(DHGA),该框架使每个节点能够共同关注其邻居的异构和动态性。
DHGAS有三个目标:
1)通过注意力机制捕获动态异构信息,即DHGA框架,它的核心思想是统一时空聚合,并通过基于注意力的信息传递机制联合的整合来自邻居节点的动态和异构信息,使用节点映射函数来计算注意力机制中Query-Key-Value的三个向量,然后使用关系映射函数计算注意力机制中向量的分数,最后通过正则化这个分数和聚合所有邻居实现带时间与类型特性的节点更新;
2)获得一个基于注意力的简洁而又有强大表达能力的搜索空间。具体来说,定位空间(Localization Space)决定什么类型的边和时间戳需要在注意力机制中计算,以减少参数的数量;参数化空间(Parameterization Space)来搜索如何计算注意力函数,这两个空间平衡了模型的复杂性和表达能力。论文中证明,DHGAS的搜索空间可以包含许多经典的图神经网络和动态异构图神经网络作为特例;
3)获得高效的搜索策略,对搜索空间使用启发式约束来去除无效或低效率的架构,采用one-shot神经网络架构搜索算法来加快搜索过程,使用超网络将NAS的双层优化问题转为one-shot NAS问题,超网络可以用不同的方法来联合优化映射函数中混合的权重和所有参数。为了使超网络的训练更稳定,将训练过程分为三阶段:节点参数化、关系参数化和定位搜索。
从实验结果看,DHGAS在不同类型的下游任务中显著优于基线方法,包括节点分类、链接预测、节点回归等;对实验结果进一步分析,通过自动化设计的神经网络架构具有复杂性,注意力机制的设置也是人无法完成定义的。
03
可扩展性
面对现实中十亿级规模的真实网络, 将Graph NAS应用到大规模图面临可扩展性的挑战。基于梯度的Graph NAS是最有可能的途径。之前基于梯度的Graph NAS简单来说是合并搜索空间中所有可能的算子形成Supernet,使用微分的方法对超网络进行训练。但是直接将超网络在大规模图数据上进行训练,存在两个挑战:一是最直接地对全图训练存在计算瓶颈,对计算资源消耗很大;二是借鉴为GNN设计的采样策略,直接将这些策略用于大图的超网络训练,问题是会带来不一致性问题,即使用采样策略训练得到的超网络和预期结果不一致。
下面介绍作者及其团队提出的Graph ArchitectUre Search at Scale (GAUSS)模型,来应对以上两个问题,详见论文:Large-scale Graph Neural Architecture Search. ICML, 2022. 核心思想是对图结构和架构进行联合采样的策略,通过两者之间良好的适应性来解决一致性问题,如下图7所示。
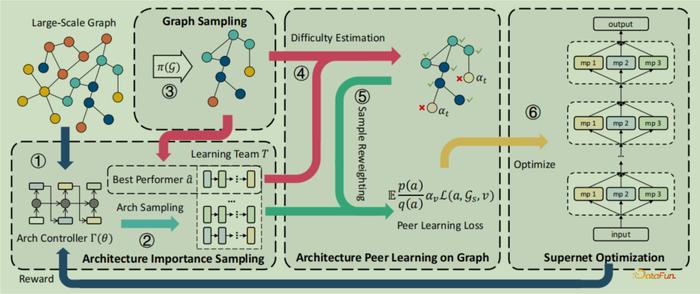 图7:在GAUSS上基于联合架构-图采样的超网络训练
图7:在GAUSS上基于联合架构-图采样的超网络训练在GAUSS上基于架构-子图联合采样的超网络训练,1)架构重要性采样,它在统计学中是非常成熟的领域,通过重要性采样实现超网络训练更加稳定的目标。具体实现是首先进行图采样,和GNN中方法类似,然后采用强化学习+控制器的策略来学习proposal distribution,使用奖励函数来优化学习过程,GRU控制器可以看作是参数化分布用来模拟序列层的操作选择;2)图上的架构同辈学习(peer learning)理念,使优化目标平滑和训练稳定。同辈学习过程先形成一个学习群体,模仿教育学中同辈学习过程,高年级帮助低年级学生的学习,通过施加不同的权重实现学习从易到难的过程,从而使学习目标更平滑,学习群体则通过前面的架构重要性采样获得;3)在采样的架构和子图上,使用反向传播算法对超网络进行训练。
从实验结果来看,模型可处理图数据的规模比之前方法提升高达1000倍,首次使用单个GPU(V100+32GB内存)可以处理十亿级规模图的搜索,在5个数据集上对比基线方法效果更优。
04
鲁棒性挑战
鲁棒性的挑战有两个方面:一是数据分布偏移(distribution shift),即训练图和测试图数据的分布发生偏移,例如训练图较小但测试图较大、训练图和测试图在结构上或节点特征上产生非常大的差异。分布偏移导致训练图上搜索得出的最优架构,其在未知的测试图上的应用效果无法得到保障;二是对抗攻击,对图添加扰动后导致图神经网络模型预测结果发生较大变化,例如新增边或改变节点特征,主要对欺诈检测或网络安全等风险敏感领域带来挑战。
首先针对数据分布偏移的鲁棒性,作者及其团队提出了GRACES(Graph neuRal Architecture Customization with disEntangled Self-supervised learning)模型,详见论文:Graph Neural Architecture Search under Distribution Shifts. ICML, 2022. 核心思想是针对每个未知分布的图实例定制最合适的GNN架构,实现自适应的、为变化后的分布偏移的图设计最适合的GNN,如下图8所示。
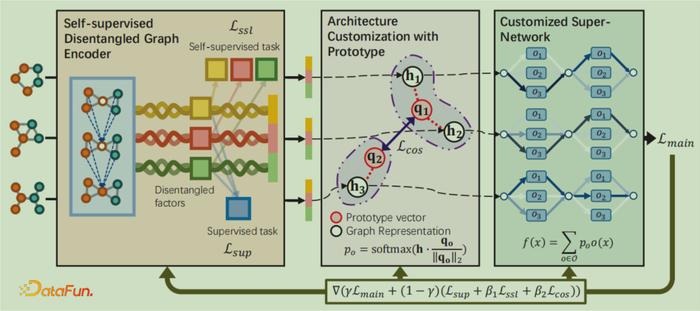
图8:GRACES模型架构图
在GRACES模型中,1)第一部分是模型的编码器Encoder,为了学习每个图的向量表征,这个表征应当反映图最本质的属性,使模型后面可以根据图的表征来定制化最适合的GNN架构。但是,图具有复杂的不同特性给学习过程带来挑战。GRACES通过使用自监督的图解耦编码器应对挑战,即使用解耦GNN作为编码器,并使用自监督学习和监督学习过程得到编码器参数;2)第二部分是定制化GNN架构,基于同质性假设:相似特征的图会需要相似GNN架构,采用基于原型向量的方法,找到和图表征相似度最大的架构,并通过设置正则项来避免模型塌缩;3)最后结合以上两个部分联合学习定制化的架构和对应的参数,使用定制化的超网络,并通过将以上两个部分中所有损失函数进行带权重的叠加实现端到端的优化。
从实验结果来看,在存在数据偏移的模拟数据集和真实数据集上,GRACES对比其他方法都有明显提升,通过可视化展示验证GRACES根据图的不同性质对GNN架构实现了定制化。
针对对抗攻击的鲁棒性工作,作者及其团队提出了G-RNA(Robust Neural Architecture search framework for Graph neural networks)模型,详见论文:Adversarially Robust Neural Architecture Search for Graph Neural Networks. CVPR, 2023. 核心思想是在图神经架构搜索中建立鲁棒性的搜索空间和搜索策略,如图9所示。
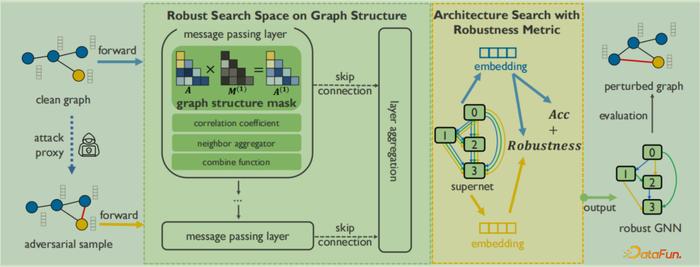
图9:G-RNA整体框架图
在G-RNA中,1)鲁棒性的搜索空间,主要考虑图结构的噪音问题,搜索空间包含6个可调组件,其中包含了图结构“掩码”,这个“掩码”专门针对对抗攻击的影响而设计,以去除噪音对图结构的影响。图结构“掩码”算子有5个:Identity、LRA、NFS、NIE、VPO,此框架的搜索空间可囊括一些经典的手动设计的GNN和最先进的鲁棒的GNN;2)搜索策略的鲁棒性指标,通过鲁棒性指标来评价搜索得到的模型是否具有鲁棒性,使用Kullback-Leibler (KL) 距离计算模型在给定干净数据和被扰动数据之间预测的差异性,同时通过代理模型(surrogate model)优化计算过程,并证明这个鲁棒性指标具有物理含义。将架构的鲁棒性和准确性结合作为搜索目标,对多目标优化过程采用了进化算法作为搜索策略。
从实验结果来看,在多方面对抗攻击的情况下,G-RNA比之前的方法都有明显的提升。
05
AutoGL库和GNAS评估
比较常用的图开源库有斯坦福的PyG(PyTorch Geometric)、亚马逊的DGL(Deep Graph Library)等,自动机器学习的开源库有微软的NNI(neural network intelligence)等,但是针对图的自动机器学习库之前还没有。图机器学习与自动机器学习间的鸿沟使该问题具有挑战性。
作者及其团队开发了首个专用于自动图机器学习开源库AutoGL,从2020年12月发布第一版,2023年下旬将发布最新版本V0.6,代码开源且具有详细文档,采用模块化的设计理念降低耦合性、提高可扩展性,链接为https://github.com/THUMNLab/AutoGL,目前也在国产开源平台GitLink进行部署,链接:https://www.gitlink.org.cn/THUMNLab/AutoGL。
AutoGL的整体框架如图10所示。AutoGL整体架构有三层,底层通过PyG或DGL与硬件进行交互,中间为AutoGL自动化解决方案,上层是节点分类、链接预测、图分类、异质图节点分类等应用。AutoGL解决方案首先在AutoGL Dataset模块对不同类型的图数据集进行管理,然后用AutoGL Solver提供了高层的API来控制整个流水线,它包含了5个功能模块,分别为自动特征工程AutoFeature Engineering、神经架构搜索NAS、超参数优化Hyper-Parameter Optimization、图模型训练Model Training和图模型的自动集成AutoEnsemble,覆盖了目前主流的自动图机器学习范式。
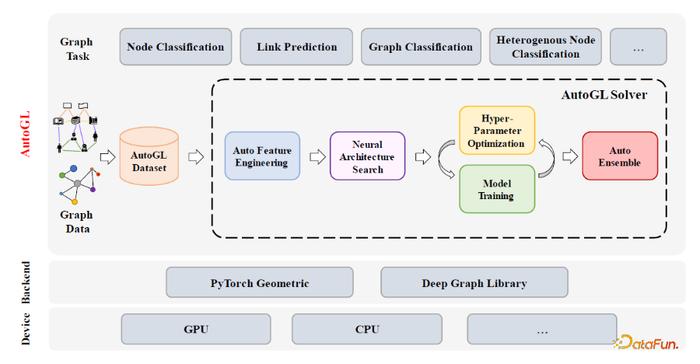 图10:AutoGL框架图
图10:AutoGL框架图另一方面,Graph NAS评估是一件非常困难的事情,有三个挑战:一是论文中实验结果的不可比较和不可复现,带来很多质疑;二是计算资源消耗很多,图的自动机器学习需要优化架构,比图神经网络需要更多计算资源;三是研究结果的评估方法多样,例如精度、性能、资源消耗等。作者及其团队提出NAS-Bench-Graph来解决评估问题,它是首个针对Graph NAS评估的表格式基准,详见:NAS-Bench-Graph: Benchmarking Graph Neural Architecture Search. NeurIPS, 2022. 其具有统一性、可复现性和高效性,提供了26206个架构在9个常用不同领域、不同大小的数据集的评测结果,搜索空间使用9个宏观架构,覆盖了具有代表性的图神经网络的7个算子。该库也兼容两个代表性的自动机器学习库的接口:AutoGL和NNI,十行代码左右就可读取使用。
06
Q&A
Q1:在工业上的应用情况有哪些?您的工作落地实施时,在更大规模图上搜索效率如何?面对不同数据集、不同任务时上可迁移性如何?
A:一直想推动自动图机器学习的真实应用,目前和阿里的风控相关部门在应用上有合作,在违禁商品的检测效果上有明显提升。落地应用要考虑对接系统、可靠性需求、数据规模等,从技术上具有挑战性。
Q2:针对每个图需要设计不同GNN架构,有没有可能只使用一个架构来解决问题?
A:Chat-GPT大模型出现后,我们团队也在思考,但是图是一种比较抽象的概念,例如图结构可能对应社交网络、也可能是生物网络,图的结构和性质是很多样的,不同于文本、视频和语音,导致目前不存在一个大模型可以在所有图上取得好的效果。如果只是针对某一领域的图进行设计可能会出现统一。
【出品人补充】未来发展可能的另一种范式是符号推理和神经网络融合,图更像是一种符号化的形式,它表达了确定性的复杂逻辑关联,NLP复杂推理任务中效果也不好。
今天的分享就到这里,谢谢大家。

分享嘉宾
INTRODUCTION
张子威
清华大学
博士后
张子威,现为清华大学计算机系博士后,本科毕业于清华大学数理基科班,博士毕业于清华大学计算机系。主要研究方向为图机器学习,包括图表征学习、图神经网络、自动图学习等。在国际顶级会议与期刊发表论文30余篇,谷歌学术引用超过3000次。曾入选博士后创新人才支持计划,获得吴文俊人工智能优秀博士学位论文提名、清华大学优秀博士毕业生、百度AI华人新星百强榜单、AI 2000学者榜单等。