时间:2024-07-31 来源:网络搜集 关于我们 0
 人工智能的起源与发展预测
人工智能的起源与发展预测
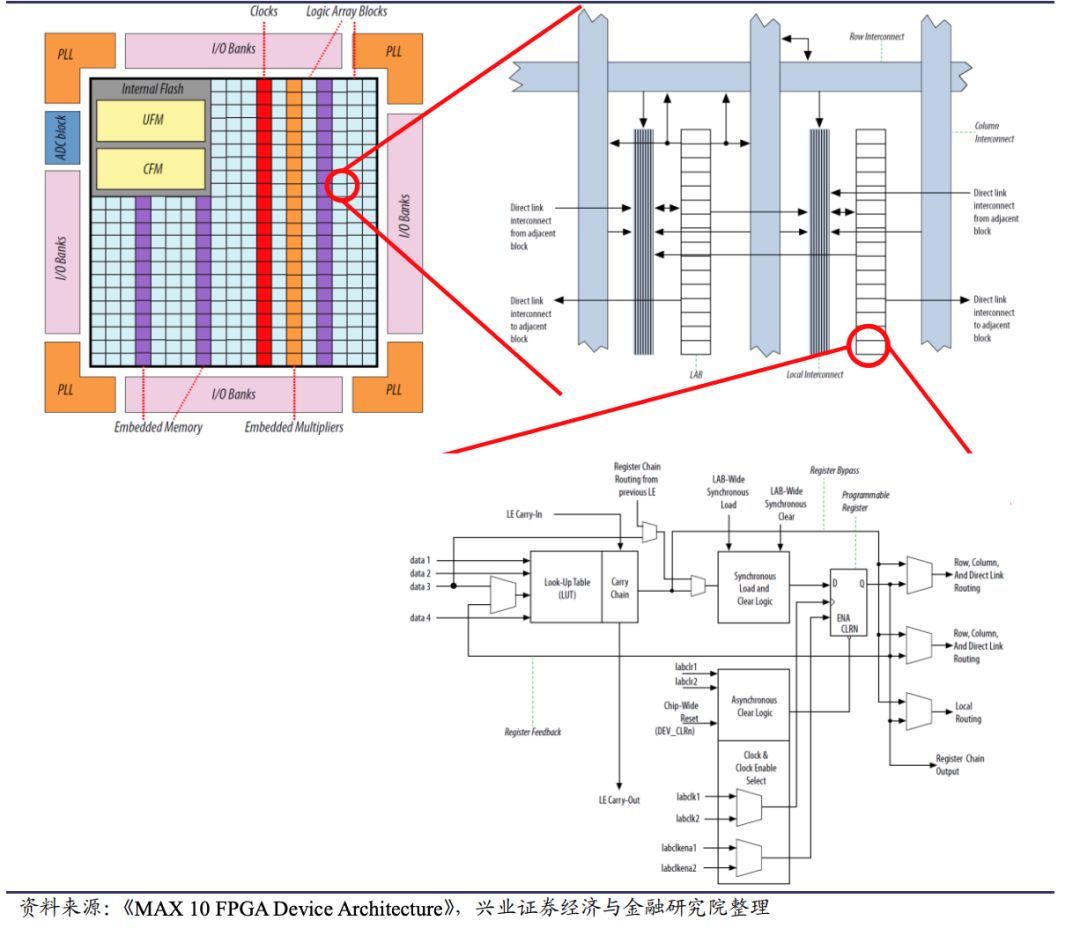
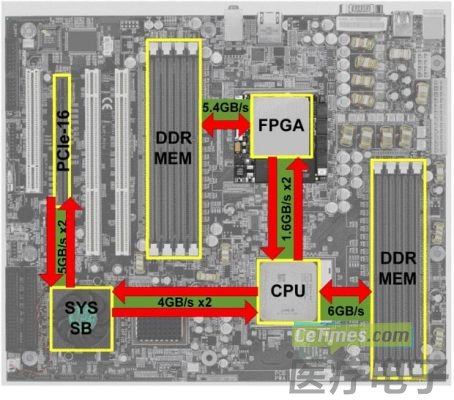
 现场可编程门阵列(FPGA)现场可编程门阵列(FPGA)是具有可编程硬件结构的集成电路类型。这与GPU和CPU不同,因为FPGA处理器内部的功能电路并非硬刻录。这使得FPGA处理器可以根据需要进行编程和更新。这也赋予了设计者从零开始构建神经网络并将FPGA构建为最适合其需求的能力。FPGA的可重新编程、可重新配置的架构为不断变化的人工智能景观提供了关键优势,使设计者能够快速测试新的和更新的算法。这在加快上市时间和节省成本方面提供了强大的竞争优势,因为不需要开发和发布新的硬件。FPGA提供了速度、可编程性和灵活性的结合,通过减少应用特定集成电路(ASICs)开发中固有的成本和复杂性,实现了性能效率。 图形处理器(GPU)图形处理器(GPU)最初是为生成计算机图形、虚拟现实训练环境和依赖于绘制几何对象、光照和颜色深度的高级计算的视频而开发的。由于GPU专为快速处理渲染视频和图形中使用的大量数据而设计,它们可以执行这些操作。它们强大的计算能力使其在机器学习和人工智能应用中备受欢迎。 中央处理器CPU中央处理器(CPU)是许多设备中使用的标准处理器。与FPGA和GPU相比,CPU的架构具有为顺序串行处理优化的有限数量的核心。Arm®处理器可能是一个例外,因为它们采用了单指令多数据(SIMD)架构的强大实现,该架构允许同时操作多个数据点,但其性能仍不可与GPU或FPGA相提并论。 微型机器学习(TinyML)被视为人工智能发展的下一个进化阶段,TinyML正经历着强劲增长。在FPGA、GPU和CPU处理器上运行的AI应用非常强大,但不能用于所有情景,如手机、无人机和可穿戴设备等。随着连接设备的广泛采用,需要进行本地数据分析,以减少对云完整功能的依赖。TinyML使得在微控制器上运行的边缘设备上实现低延迟、低功耗和低带宽的推断模型成为可能。 总得来说AI的三个主要硬件选择是:FPGA、GPU和CPU。在速度和响应时间至关重要的AI应用中,FPGA和GPU在学习和反应时间方面提供了优势。虽然GPU具有处理AI和神经网络所需的大量数据的能力,但缺点包括能源效率、热量考虑(发热)、耐久性以及更新应用程序的能力和AI算法。
现场可编程门阵列(FPGA)现场可编程门阵列(FPGA)是具有可编程硬件结构的集成电路类型。这与GPU和CPU不同,因为FPGA处理器内部的功能电路并非硬刻录。这使得FPGA处理器可以根据需要进行编程和更新。这也赋予了设计者从零开始构建神经网络并将FPGA构建为最适合其需求的能力。FPGA的可重新编程、可重新配置的架构为不断变化的人工智能景观提供了关键优势,使设计者能够快速测试新的和更新的算法。这在加快上市时间和节省成本方面提供了强大的竞争优势,因为不需要开发和发布新的硬件。FPGA提供了速度、可编程性和灵活性的结合,通过减少应用特定集成电路(ASICs)开发中固有的成本和复杂性,实现了性能效率。 图形处理器(GPU)图形处理器(GPU)最初是为生成计算机图形、虚拟现实训练环境和依赖于绘制几何对象、光照和颜色深度的高级计算的视频而开发的。由于GPU专为快速处理渲染视频和图形中使用的大量数据而设计,它们可以执行这些操作。它们强大的计算能力使其在机器学习和人工智能应用中备受欢迎。 中央处理器CPU中央处理器(CPU)是许多设备中使用的标准处理器。与FPGA和GPU相比,CPU的架构具有为顺序串行处理优化的有限数量的核心。Arm®处理器可能是一个例外,因为它们采用了单指令多数据(SIMD)架构的强大实现,该架构允许同时操作多个数据点,但其性能仍不可与GPU或FPGA相提并论。 微型机器学习(TinyML)被视为人工智能发展的下一个进化阶段,TinyML正经历着强劲增长。在FPGA、GPU和CPU处理器上运行的AI应用非常强大,但不能用于所有情景,如手机、无人机和可穿戴设备等。随着连接设备的广泛采用,需要进行本地数据分析,以减少对云完整功能的依赖。TinyML使得在微控制器上运行的边缘设备上实现低延迟、低功耗和低带宽的推断模型成为可能。 总得来说AI的三个主要硬件选择是:FPGA、GPU和CPU。在速度和响应时间至关重要的AI应用中,FPGA和GPU在学习和反应时间方面提供了优势。虽然GPU具有处理AI和神经网络所需的大量数据的能力,但缺点包括能源效率、热量考虑(发热)、耐久性以及更新应用程序的能力和AI算法。都看到这儿了,点个关注吧!!
点击图片关注“成电国芯FPGA人才培养”小程序/服务号
详情咨询 :
高老师:18935839030 | V信:gmy18935839030